はじめに
AIエージェント、今流行っていますよね。 私もChatGPTにCopilot、Claude、Google Geminiなど日々仕事に、プライベートに便利に使っています。
これらは非常に便利ですし、ものすごいスピードで進化し続けています。 しかし、チャットなどでやりとりした会話の内容やアップロードしたファイルはサービスを提供している企業に送信されます。 ファイルや会話データの取り扱いについては利用規約で定められていますが、実際どのように取り扱われるかはその企業を信じるしかありません。
AWSのようなクラウド環境を手元の環境で動かしたいというアイデアからOpenStackができたように、このようなAIチャットボットやLLM(大規模言語モデル)を自分の環境で動かしたいという需要はあると思います。 それを実現するのがローカルLLMであり、いくつかのソフトウェアを利用することで普段使いの環境で簡単に使うことができます。
有名なものとしては次の二つとかでしょうか。探せば他にも有用なソフトウェアがあるかもしれません。
Ollamaはローカル環境で大規模言語モデルを簡単に取り扱えるオープンソースツールです。 ソフトウェア自体は無料で使え、いくつかある中からモデルを選んで使い始める感じです。 CLIとGUIツールが提供されていて、どちらでも使えます。
OllamaはほかにOllama Turboというモデルを動かすためのハードウェア貸し出しのサービスをしているようですね。 月20ドルだと、ChatGPT PlusやMicrosoft Copilot Pro、Claude Proなどと一緒の価格ですね。
LM Studioもローカル環境で大規模言語モデルを簡単に取り扱えるオープンソースツールの一つで、GUIで使うもののようです。個人での利用は無料で、企業や組織で使う場合は元々有償でしたが、最近無料になりました。
どちらも気になるツールではありますが、今回はOllamaを使ってみます。
Ollamaをセットアップする
Ollamaをダウンロードします。
インストール方法はいくつかありますので、何らかの方法でOllamaをインストールします。
Ollamaを起動するとGUIアプリケーションが起動してアプリからLLMが使えますが、初回起動後はCLIも使えるようになります。 利用できない場合は端末を開き直せば使えると思います。
% ollama --version ollama version is 0.11.2
CLIで使えるモデルは、こちらに一覧があります。
まず始めに使うなら、小さめのモデルを使ってみましょう。
% ollama run gemma3:1b
次のように実行すると、モデルのダウンロードが始まります。「Send a message」と表示されたら、モデルの準備は完了です。
% ollama run gemma3:1b (サイズは815MB) pulling manifest pulling 7cd4618c1faf: 78% ▕██████████████ ▏ 634 MB/815 MB 107 MB/s 1s ... verifying sha256 digest writing manifest success >>> Send a message (/? for help)
OllamaをCLIで使う
なにか入力してみましょう。
>>> Pythonでhello worldを出力するコードを生成
print("Hello, world!")
これがPythonで"Hello, world!"を出力する最も簡単なコードです。
**解説:**
* `print()` は、Python の組み込み関数で、指定された値を画面に表示する役割を
持っています。
* `"Hello, world!"` は、表示する文字列です。 Python では、文字列を引用符で
囲むと、その文字列を意味のある単語として扱います。
**実行方法:**
1. このコードを `hello.py` のようなファイル名で保存します。
2. ターミナルまたはコマンドプロンプトを開きます。
3. `python hello.py` と入力して実行します。
すると、コンソールに "Hello, world!" と表示されます。
おお、動きましたね。ちゃんと日本語で質問しても日本語で回答されました。 比較的軽めのモデルですが、なかなか賢いですね。 私なんかより物知りです(負け)。
もう一つ質問してみましょう。
>>> touchコマンドについて、日本語で概要と使い方についてまとめてください。
## 実行する「touch」コマンドの概要と使い方
**概要**
`touch` コマンドは、指定されたファイルに、そのファイルに書き込む内容(通常は
空のファイル)を生成するコマンドです。 これは、新規ファイルを作成する際の便
利なツールであり、ファイルが存在しない場合に、ファイルを作成して内容を空白に
設定する際に便利です。 `touch` コマンドは、ファイルの存在確認を自動化したり
、ファイルが存在しない場合にそれを自動的に作成したりする役割があります。
**使い方**
基本的な使用方法としては、以下のようになります。
1. **ターミナル/コマンドプロンプトで実行:**
* ターミナル(Linux/macOS)またはコマンドプロンプト(Windows)で、
`touch <ファイル名>` と入力します。
* `<ファイル名>` は、作成したいファイルのファイル名に置き換えます。
例: `touch my_new_file.txt`
2. **ファイルが作成される:**
* `touch` コマンドを実行すると、指定されたファイルが作成されます。
* ファイルがすでに存在する場合、内容は空文字列に設定されます。
3. **ファイルの存在確認:**
* `touch <ファイル名>` を実行すると、ファイルが既に存在するかどうかをチェ
ックできます。
* ファイルが存在しない場合は、新しいファイルが作成されます。
**例:**
* **新規ファイル作成:** `touch new_document.txt`
* **ファイルが存在しない場合の確認:** `touch -t 2023102710000
new_document.txt` (日付を調整して日付を задайте)
* **既存のファイルの内容を空白に置き換える:** `touch my_file.txt`
(my_file.txt が既に存在する場合、そのファイルの内容が空になります)
**補足:**
* `touch` コマンドは、ファイルの権限を自動的に設定します。
* `touch` コマンドは、ファイルの作成時にファイルサイズを自動的に設定します
。
**利点:**
* **ファイルの存在チェック:** ファイルが存在しない場合に自動的に作成できる
ため、ファイルが作成されるかどうかを簡単に確認できます。
* **ファイルの作成の簡素化:** 新しいファイルを作成する際に、ファイルが存在
しない場合に自動的に作成してくれるため、手作業を省けます。
* **効率的なファイル管理:** ファイル作成のプロセスを自動化できるため、フ
ァイル管理を効率化できます。
**まとめ:**
`touch` コマンドは、ファイル作成の初期化やファイルが存在しない場合のチェック
、ファイル作成の簡素化など、様々な場面で便利なコマンドです。 日常的に使われ
ることが多いコマンドです
今度は同じモデルを使って「pythonで1を入力するとhelloworldを表示し、2を押すと終わるコードを作成してください。」と質問してみます。 先ほどはHello worldを出力するだけでしたが、もう少し高度な事を聞いてみます。その結果がこれです。
import sys def main(): if 1 <= 2: print("helloworld") else: print("終了") if __name__ == "__main__": main()
この後説明が続きますが、今回は省略します。
生成されたコードは実行しないでもわかると思いますが、残念ながら適切なコードを生成できませんでした。 このあと「実行したらhelloworldと表示されてプログラムが終了してしまいました。コードが適切ではないようです」とプロンプトに入力すると、「申し訳ありません。私の以前の回答で誤ったコードを提示してしまいました。」とは言うものの、提示されるコードは全く同じの繰り返しと言う状態でした。 何度かトライすると、もう少しマシなコードを生成する事もありましたけど。
とはいえ、コード生成に適切なモデルを選ぶべきかもしれません。 いったん止めて、別のモデルを選んでみます。
>>> /bye % ollama run codegemma:2b (サイズは1.6GB)
もう一度同じものを入力してみます。 「pythonで1を入力するとhelloworldを表示し、2を押すと終わるコードを作成してください。」 今度はそれっぽく動くコードが生成されました。ただ、説明とかはいっさいない感じですね。
print("入力してください")
print("入力:")
a=int(input())
if a==1:
print("hello world")
elif a==2:
print("終了")
exit()
出てきた回答の中で笑ってしまったのがこの結果です。ちょっとw
>>> pythonで1を入力するとhelloworldを表示し、2を押すと終わるコードを作成してください。 /pythonで1を入力するとhelloworldを表示し、2を押すと終わるコード.py
Metaのllama3.2:1bを使ってみる
Metaのllama3.2:1bを使ってみます。
>>> /bye % ollama run llama3.2:1b (サイズは1.3GB)
表示された結果
以下はPythonの例です。
print("Hello, World!") # 1. 1 を入力すると "Hello, World!" が表示されます。 while True: # 2. 2 を押すと Loop が続きます。 print("\nPress Enter to exit...") input() # Enter Key の値を受け取り、Enter key press後は Loop を終了します。
このコードでは、次のようになります。
$ python helloworld.py Hello, World! Press Enter to exit... $ python helloworld.py Press Enter to exit...
モデルによって色々な性格がありますね。 特にllama3.2:1bは、同じ質問を実行するたびに色々な方法で実装する例を出してくれます。 それがいいかどうかは時と場合によるので、いつも同じ結果を求める場合はコード生成に特化したモデルを選んだほうが良いのかもしれません。
幅広い選択肢の中から選んで対話できるのは、LLMを自分の環境で動かすメリットなのかもしれません。
Ollamaでgpt-ossを使う
gpt-ossはOpenAIがリリースした強力な推論、エージェント タスク、および多目的な開発者ユースケース向けに設計されたモデルです。昨日発表されたばかりですが、Ollamaでgpt-ossを使う事ができるようです。
GPUが実装された環境ではより大規模なモデルを使えそうですが、特別なGPUが実装されていない環境でも動かせるモデルも提供されているようです。
20Bの方を動かしてみましょう...と言いたいところですが手元の端末は16GBのメモリーを実装しているものの、gpt-ossを実行するには結構メモリーが必要らしくで、うまく動かすことはできませんでした。
機会があれば、メモリをたくさん積んだ環境で試してみようと思います。
[8/8 追記]
手元のMac (M4 Mac mini)で20Bの方で動かす事ができました。ただ、結構ギリギリカツカツで動いています。 サイズが大きいからなんでも完璧に答えられるかというとそういうわけではなくて、あくまでインプットしたテキストに対してどれだけたくさん推論できるかと言うのが重要です。「日本で高い山トップ3は?」みたいなインプットをすると、色々推論しているところが見れて楽しいです。ここら辺はモデルによって性格があるので、楽しいところですね。
数学的な事やプログラミングコードについて聞くと、かなり正確な回答をしてくれます。 その分野では有用な気がします。
VSCodeでOllamaを使う
インストールしたOllamaとダウンロードしたモデルは、VSCodeの中でも使えるようです。 VSCodeではVSCodeの中でターミナルを開くことができるので、その方法でLLMと対話することはできます。
ただせっかくならVSCodeのGitHub Copilot Chatのように、GUIからLLMにアクセスしてみたいですよね。 調べたところ、VSCodeにGitHub Copilot拡張がインストールされていればその他のモデルを選んで「Ollama」を使うことができるとのことです。
まずはモデルの管理をクリックします。 次に「Ollama」を選び、モデルを選ぶと使えるのだとか。
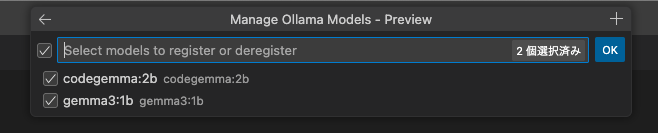
その後、Copilot Chatのモデル選択でLLMを選択すると良いそうです。

自分の開発環境に余裕があれば、これでAIを活用した開発が手軽にできるのかもしれません。 Remote DevelopmentとかDev Containersを組み合わせればここら辺は便利になったりするのかなあ。
VSCode GitHub CopilotのAgent,Ask,Editモードについて
さっくり言うとこんな感じです。 追加したOllamaは、現時点ではAskモードで選択できるようです。
| mode | 概要 |
|---|---|
| Ask | チャットでやり取りするモード。CLIや専用のアプリで使うのと同じようなイメージ |
| Agent | Copilot Chatの中で最も強力かつ新しいモード |
| Edit | プロジェクト内でチャットを開いてコード補完とか修正をするようなモード |
詳しくはこちらのブログが参考になりました。
ただし、実際の動きとしてはCLIや専用のアプリで使ったときと比べて質問に対する回答が不十分でした。これはOllamaや利用しているモデルのせいではなく、GitHub Copilot側で外部のAIエンジンを使う場合の問題であるような気がします。
実際動かしてみたときの評価は次のような感じです。 たとえば次のような質問をしてみます。
VSCode GitHub Copilotで質問をしてみます。 「Golangで1を入力するとhelloworldを表示し、2を押すと終わるコードを作成してください。」
回答は次のように出てきたが、何か壊れていますね。
package main
import "fmt"
func main() {
fmt.Println("helloworld")
}
...existing code...
filepath: untitled:Untitled-1
コンソールや回答を見ると何か動いたようですが、コードは何か中途半端に終わっています。 Hello worldは表示されそうですけどね。ちなみに「codegemmma:2b」を選んだ場合は何も出力してくれませんでした。
ちなみにエンジンをGPT-4.1に切り替えると、こんなコードを生成しました。 他のAIエージェントと比べると、GitHub Copilot Chatの回答はコードのみアウトプットする場合が多くてシンプルですね。
package main import ( "bufio" "fmt" "os" "strings" ) func main() { reader := bufio.NewReader(os.Stdin) for { fmt.Println("1: helloworldを表示") fmt.Println("2: 終了") fmt.Print("番号を入力してください: ") input, _ := reader.ReadString('\n') input = strings.TrimSpace(input) switch input { case "1": fmt.Println("helloworld") case "2": fmt.Println("終了します。") return default: fmt.Println("無効な入力です。1か2を入力してください。") } } }
VSCodeでローカルLLMを使うには、他の方法を使ったほうが良さそうですね。 もしくはVSCode内でターミナルを開いてやり取りするほうが、今のところは役立ちそうです。
しかし、CLIやGUIアプリでチャットをしながら色々な問題の解決をするのに役立ちそうです。 ローカルLLMはClaudeやCopilot等と平行して使っていこうと思っています。 また、速いうちにメモリーをたくさん積んだ環境を用意して、Ollamaでgpt-ossを使うのを試してみたいと思います。 NVIDIA GPUを積んだ環境を用意するのも良いですね。